Unsupervised Memorability Modeling from Tip-of-the-Tongue Retrieval Queries
Abstract
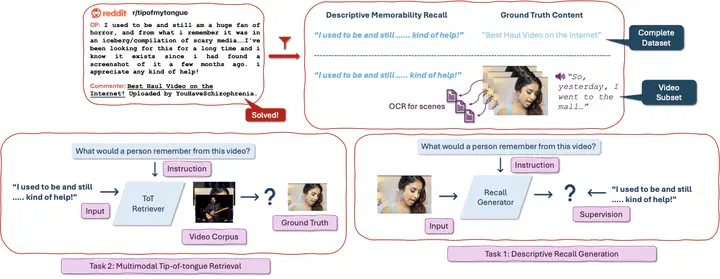
Visual content memorability has intrigued the scientific community for decades, with applications ranging widely, from understanding nuanced aspects of human memory to enhancing content design. A significant challenge in progressing the field lies in the expensive process of collecting memorability annotations from humans. This limits the diversity and scalability of datasets for modeling visual content memorability. Most existing datasets are limited to collecting aggregate memorability scores for visual content, not capturing the nuanced memorability signals present in natural, open-ended recall descriptions. In this work, we introduce the first large-scale unsupervised dataset designed explicitly for modeling visual memorability signals, containing over 82,000 videos, accompanied by descriptive recall data. We leverage tip-of-the-tongue (ToT) retrieval queries from online platforms such as Reddit. We demonstrate that our unsupervised dataset provides rich signals for two memorability-related tasks: recall generation and ToT retrieval. Large vision-language models fine-tuned on our dataset outperform state-of-the-art models such as GPT-4o in generating open-ended memorability descriptions for visual content. We also employ a contrastive training strategy to create the first model capable of performing multimodal ToT retrieval. Our dataset and models present a novel direction, facilitating progress in visual content memorability research.
Yaman Kumar Singla
Senior Research Scientist
Sudhir Yarram
Research Scientist
Somesh Singh
Research Associate
My research interests include Large Language and Vision Models, reasoning, planning and its intersection with human behavior.